
[I was invited to deliver the inaugural talk in a series hosted for Baker-Berry Library at Dartmouth College. Many thanks to Laura Braunstein for organizing the event and to those who attended. And special thanks to my collaborators at CU Libraries, Deborah Hollis and Holley Long, for their continued support and teamwork.]
Textual digitization projects of a large scale can take a long time. As you know, they take an even longer time when the text cannot be scanned and OCR’d and manuscript transcription is required. Today I want to take advantage of this middle stage of a long-term textual digitization project I manage, called the Stainforth Library of Women’s Writing, to swap expertise with you. This digital library is under construction right now, and it’s the perfect time to pause, appreciate our data and editorial carnage, share our process and the hunches I’m operating on, and ask different audiences what you think of it and how we can make it better. My plan for our time today is to introduce my project and tell you a little bit about the history of how it got off the ground. And then I’m going to give you a chance to pretend my project is yours. We’ll compare your approaches to editing and delivering our data with what we have done or hope to do.
Throughout, while we talk about options for processes and the choices I’ve made, I am hoping that we can think together about the future of textual digitization projects from a pragmatic point of view that takes small budgets, time constraints, growing numbers of untenured faculty, and the job market into account. That is: you know and I know, from experience, the amount of labor and critical thinking that go into producing digital editions of a text or a collection of texts, such as Dartmouth’s John McCoy Family papers and the Occom Circle Project. I think that it is important to imagine the upper limits of what a digital archive can do for researchers, such as provide 3D representations of digital objects. But I also want to offer an idea for how scholars like myself, without a sizable markup team, can generate a corpus of edited data and deliver it for research and teaching in a timely manner.
I will argue today that producing and releasing one’s data first, and the more marked-up data set in a linked digital archive second, is a much needed new model of data curation that may be of particular interest to untenured digital humanists, of which I am one. This two-phase release model responds to the constrained institutional ecosystem in which many digital humanists are working with limited budgets, time, and help, and while satisfying requirements for hiring, tenure, and promotion that rest on peer-reviewed essays and books. This model, which I’ll be calling the “cookie-dough” model just for this talk, helps us make more useful digital objects with the same amount of data. It also helps create tangible traditional scholarly products from our digital curation work sooner, before we finish creating an interface, which can take a very long time. So: first, a project introduction, second, we’ll talk about processes together in a workshop, and then I’ll conclude.
What is the Stainforth Library of Women’s Writing?

The Stainforth Library of Women’s Writing is a textual digitization project based in Dartmouth as well as at CU-Boulder. As the only full-time Stainforther, I also function as a project manager. (Though, like most digital humanists who are also literary scholars, I have to dedicate time to teaching and research/writing on non-Stainforth literary topics, as well.) I have two primary co-editors who also give tremendous time, expertise, and heart to this project: Deborah Hollis, who oversees the Department of Special Collections and Preservation at CU Libraries, and Holley Long, CU Libraries’ Digital Initiatives Librarian. Collaboration with the library makes this DH project possible. Together, we are using Stainforth’s manuscript library catalog to reconstruct a digital model slash electronic archive of the library he collected in the 19th century. In other words, we are creating an electronic legacy library.
Stainforth’s library is unique and worth the effort to digitally reconstruct for a number of reasons including its size, contents, and the tenacious reputation of the collector. 
Francis John Stainforth was a British Anglican priest, baptized in 1797 and deceased in 1866. Raised in an upper-middle-class family, he served in the Army in India, married his first wife while abroad, and returned to complete his divinity degree at Oxford and minister as a curate in the greater London area for the next 30 years until his death.
Aside from his duties as a priest, he was an avid, serious collector of shells as well as stamps. His collections contributed to important catalogs for conchologists and philatelists at the time, and he helped found the Royal Philatelic Society of London, the oldest stamp collecting society in the world.


Though his shell and stamps joined some of the most famous collections of his day, his library was arguably his most historically significant collection.
His collection had a defined and important scope. He collected every title and edition of poetry and plays by women authors that he was able to find in print and manuscript form that circulated in London in the 19th century. This amounted to over 6,000 titles. It was the largest 19th-century private library of books by women writers. The catalog lists a wide range of authors of various nationalities who published in five different centuries. He also gathered clippings of shorter pieces by women that appeared in periodicals as well as some portraits of women writers. Women authors knew about the collector and sometimes even sent their poetry to him directly for inclusion in the collection. In sum, the collection provides 21st-century scholars with a newly recovered bird’s-eye view of the scope and depth of women writers presence in the London book market through 1866.

The Stainforth editors’ high regard for the library catalog as a useful tool for measuring women writers’ contributions to the book market has historical precedence. In the late eighteenth and early nineteenth centuries, bibliographers considered library catalogs, like Stainforth’s, to calculate the impact of print technologies on the book market and on learning in general. For example, Romantic-era author Isaac D’Israeli cites a mathematician who used library catalogs to calculate the number of titles produced in the first 400 years of print history:
This future universal inundation of books, this superfluity of knowledge, in billions, and trillions, overwhelms the imagination! It is now about four hundred years since the art of multiplying books has been discovered ; and an arithmetician has attempted to calculate the incalculable of these four ages of typography, which he discovers have actually produced 3,641,960 works! Taking each work at three volumes, and reckoning only each impression to consist of three hundred copies, which is too little, the actual amount from the presses of Europe will give to 1816—3,277,764,000 volumes! each of which being an inch thick, if placed on a line, would cover 6,069 leagues! (“A Bibliognoste” 248-49)
All berserk math aside, the 6,000 titles in the digital Stainforth library will provide an important counterview to most electronic projects that focus on women’s writing. These are built usually with contemporary scholarly agendas in mind — whether it’s to offer biographical data on women writers of the British Isles from the beginnings to the present, as The Orlando Project does, or to provide edited full-texts written by women writers in English, as the Women Writers Project does. In contrast, the collection of titles and authors that will appear in the Stainforth digital library were collected in the early-to-mid 19th century, and they reflect the historical conditions of the book market for women writers at that time. The collection also reflects Stainforth’s agenda to *try* to collect all of the available editions of works by women poets and dramatists that he could. Many thought he came close, but he did not manage to collect everything. Don’t tell him that.

The best way to see who and what Stainforth collected is to take a close look at his manuscript. This youtube video shows exactly how this manuscript works — it has a special format, called tête–bêche, which means “head-to-toe.” CU-Boulder owns the original manuscript catalog for Stainforth’s library, in which he logged the publication information and shelf location for each volume in his collection. This catalog is the blueprint for reconstructing Stainforth’s library.
The manuscript tells us not only what he owned and how he organized his collection, but what he sought to collect and succeeded in acquiring. In the back of the manuscript catalog, he kept a substantial wish list of around 870 books he hoped to add to his shelves. He crossed many of them off, about half of the books on his wishlist, and you can see where he added them to the list of books he owned.

When Stainforth died in 1867, the auction house Sotheby, Wilkinson, and Hodge auctioned off his library contents. The auction lasted for a week and sold in over 3,000 lots. Since the 19th century, book collectors and authors researching women writers have used the auction catalog as the de facto record of Stainforth’s library. The auction catalog is very different than his manuscript library catalog and not a faithful representation of his collection. This is another reason why we are embarking on this project: to publish a corrective to the auction catalog, which is the only representation of the library that bibliographers and scholars have had access to in the past.
 The auction catalog omits some of the most interesting and important data in Stainforth’s manuscript catalog. These include the shelf marks as well as his wish list. The auctioneers’ book also contains works that Stainforth doesn’t list in his catalog. And it organizes the library differently because the auction house has a very different goal than the collector: they arrange their catalog to attract buyers to sell the library to pieces. They don’t want it to last or to gather books that are alike, as Stainforth did. They want to dissolve the library and make money off of it in the process.
The auction catalog omits some of the most interesting and important data in Stainforth’s manuscript catalog. These include the shelf marks as well as his wish list. The auctioneers’ book also contains works that Stainforth doesn’t list in his catalog. And it organizes the library differently because the auction house has a very different goal than the collector: they arrange their catalog to attract buyers to sell the library to pieces. They don’t want it to last or to gather books that are alike, as Stainforth did. They want to dissolve the library and make money off of it in the process.

[Pass around auction catalog: I’m passing around a hardcopy of the auction catalog going around the room, and you can see a version of it in Google Books that is kindof searchable, but not fully cleaned-up OCR.
Sotheby’s Stainforth Library Auction Catalog in Google Books
There is also a version available behind a paywall from Cengage, but the OCR is slightly better in Google Books, and that’s not saying much. Regularly, I search for a word or phrase that should be easy to find and it does not recognize it.]

Ironically, the auction catalog–printed to take the library apart–is how the record of the Stainforth library was passed on.
Stainforth’s library gets a front-page story in an 1883 issues of The Woman’s Journal that uses the catalog as data toward gaining new appreciation for the scope of women writers’ contributions to book culture.
 The author explains that she sits with the auctioneers’ catalog before her and marvels at the collection with language that treats it not as a library, but instead as a “vast and singular monument of the literary industry of English and American women” (HTJ 297). It’s as if the list represents all the women’s writing in circulation, just as Stainforth’s Wants catalog tries to do. Furthermore, the author uses the lot-numbered auctioneers’ catalog to assess the library by its numbers: “There are no less than 150 volumes by Miss Hannah More; 94 by Mrs. Elizabeth Rowe, once famed as “Philomela;” 79 by Mrs. Hemans; 66 by lady Mary Wortley Montagu; 61 by Mrs. Inchbald; 38 by Mrs. Maclean (L. E. L)” (HTJ 297). Further, the author concludes that
The author explains that she sits with the auctioneers’ catalog before her and marvels at the collection with language that treats it not as a library, but instead as a “vast and singular monument of the literary industry of English and American women” (HTJ 297). It’s as if the list represents all the women’s writing in circulation, just as Stainforth’s Wants catalog tries to do. Furthermore, the author uses the lot-numbered auctioneers’ catalog to assess the library by its numbers: “There are no less than 150 volumes by Miss Hannah More; 94 by Mrs. Elizabeth Rowe, once famed as “Philomela;” 79 by Mrs. Hemans; 66 by lady Mary Wortley Montagu; 61 by Mrs. Inchbald; 38 by Mrs. Maclean (L. E. L)” (HTJ 297). Further, the author concludes that
such a mass of literature has been collected from the works of English and American women only, and those working but in one or two departments, shows how much larger is already the contribution of that sex to literature than we recognize. I have long been hoping that some woman would arise with sufficient intellectual zeal and training to devote herself to a systematic work on the ‘Intellectual History of Woman’. [. . . ] When she arises she will find even the catalogue of this rare library to be a treasure. (HTJ 297)
It is stunning to me that the author concludes the profile of Stainforth’s library by recommending it as a source of data for a topic so broad as the “Intellectual History of Woman” – Stainforth’s library and catalog, don’t forget, only contained works in circulation by American and British women poets and playwrights; it excludes the very deep and popular pool of novelists if those authors did not also write plays and poetry. For example: Charlotte Turner Smith has entries in the catalog for her poetry, but not for her nine novels.
 The catalog’s list–though biased–was used by well-known 19th and 20th century authors and book collectors like Henry Buxton Forman. In fact, Forman used the Stainforth library in the way that we are using it: to research women writers. In his introduction to the revised biography of Percy Bysshe Shelley (1913), he recounts how he used the Sotheby’s catalog to discover works by Lady Emmeline Stuart Wortley:
The catalog’s list–though biased–was used by well-known 19th and 20th century authors and book collectors like Henry Buxton Forman. In fact, Forman used the Stainforth library in the way that we are using it: to research women writers. In his introduction to the revised biography of Percy Bysshe Shelley (1913), he recounts how he used the Sotheby’s catalog to discover works by Lady Emmeline Stuart Wortley:
It occurred to me to consult the auction catalog of the Stainforth collection of poetry by women, a collection reputed to have contained everything and anything in verse published by English or American women up to 1866. [The Stainforth auction catalog] is a thoroughly useful work of reference. […] I always have it at hand. (xv, my emphases)
So, because famous book dealers like Henry Forman used and wrote about the Stainforth library, traces of it remained such that CU Boulder’s astute director of special collections knew to buy the library catalog manuscript when a British book dealer brought it to her attention about 15 years ago.
This concludes my introduction to the project and the scope of the library we’re making into a digital archive. Right now I want to switch gears and show you how we’re building this digital library using the library catalog manuscript.
[On the list of links for this talk you will find a google doc for reference for Part II.]

Part II: Here’s My Data, How Would You Handle It?
For the second part of this session, I will break the audience up into small groups and have each group brainstorm solutions. One person in the group will type those solutions in the shared Google Doc – it’s liked on the blog post that goes along with this talk.. [Note: respondents did far more talking than typing and this turned out to be a great series of discussions, so I have summarized responses in line with the text of the talk.]
Challenge #1:
You have a 600-pg 19th c. library catalog ms to transcribe. Here it is. How would you handle the transcription process? (small groups talk and then share their thoughts)
Summary of Responses:
- Group 1: Try using Juxta: put the image in one window and the digital text in the other.
- Group 2: No precise recommendations because we kept thinking about the questions of what are the goals and audiences for the representation of the data?
- How do you anticipate how people are going to use it?
- At the beginning: how do you know how much time and effort you want to put into this?
Here’s my answer to challenge 1: A brief tour of our editing environment – you can follow along with the links on the blog post for this talk:

- Shared Google Drive folder with subfolders for data, edited content, guidelines, and our sub-projects, like the mapping project. There are many aspects of Google Drive that make me regret the decision to use it for our files. It does do some things well.
- Transcription Guidelines, with editing transcription data guidelines at the end of the file
- [We have a somewhat abandoned Basecamp account on the CU-Boulder server … I was the only one who used it for a while because I liked the to-do lists and the wiki]
- We use annotated PDF pages to organize our transcriptions by page number and line number.
- When we had trouble making out a title or a letter, we used several sources to help us decipher: the full ms page images in LUNA, Sotheby’s catalog online and in hard copy, the Orlando Project, Women Writers Online project (Northeastern), the Oxford Text Archive and EEBO/ECCO/Evans TCP archive, Worldcat, Google Books, and HathiTrust.
For example, here is Page 107 in the manuscript, and next to it I’ll put up the raw transcription of that page.


You can see how we organized our transcription files by page # and line #. The good part of this is that it does seem like an organized system that breaks up logically. On the flip side, we will have 1200 files of transcription when we’re done.
In each transcription form, we log:
- page #
- line #
- interline # (these get edited out)
- entry – this is the meat of the transcription
- Blank Line
- Strikethrough (this only pertains to the items in the back of the catalog, in the wish list)
- See reference (yes or no)
- Notes
- Editorial Record tab
Now, I made a lot of transcription decisions that were good decisions, but its more fun for you and maybe more useful if I focus on what I did wrong.
My major errors had a theme — and that was not doing a good job of preserving Stainforth’s use of the page space when turning the ms into digital text. The source of most of the errors is that our transcription philosophy changed when I adjusted our output goals. I decided mid-transcription that I wanted our transcription to be publishable as data that could be used for computational analysis before we built out the website interface or began deep encoding and linking. I feel so strongly about this goal, and I still think it’s the right decision, that the transcription errors it caused were worth it. I’ll show you some of the mistakes or consequences of this shift and how we are fixing them during the editorial phase.

Error #1: Interlines. At first, we transcribed interlines, or text added between what we call the “parent” lines, or the numbered lines, as their own line. They kept the same line number as the parent line, but when they were below the parent line they had an interline # of -1, and if they were above the parent they were interline # +1.
I knew this was trouble around page 150, by which time we noticed a pattern: we expected interlines to be full line entries, like the top example on the slide, but they were far more often just small additions or corrections above or below the line, like my second example in red on the slide above. I felt strongly that we needed to be consistent and make the same error throughout the transcription so that we could easily keep track of our errors in order to fix them as a batch, during the editing phase.

Error #2: Gaps that are repeated author names. At first, I wanted a “pure” transcription of just the writing on the page for each entry. Initially, this worked well, especially when we were simultaneously collecting data for each line in our database. But: The point at which I noticed that my initial transcription plan was a problem was when I decided I wanted to turn the transcription into data that could be used for computational analysis, or data mining. For the Stainforth manuscript, this requires that we think in terms of creating meaning on each line — a line on its own must have meaning or content that we can understand without having to refer to lines above or below it to understand it. Stainforth regularly used gaps and marks such as “Do.” or a double quotation mark to stand in for data that repeats from the line(s) above it.

It’s only recently that humanities scholars in English departments have wanted to perform computational analysis on digital collections of texts, and it’s even more recent that literary scholars have the programming skills to do this themselves. I consider myself one of these, though I’m admittedly “green”: I’m taking a Programming for Humanists online course via TAMU and learned introductory R and XQuery — just enough to know how to get started with an analysis and troubleshoot through the rest. I already have some training and practice in XSLT. Our project is rich in raw transcribed data that I can run through R or XQuery, and that I can output with XSLT. This data will help us answer a number of important questions about women writers and their texts in the 19th century book market. For example:
- What was the rough number of women poets and dramatists whose works were circulating on the London book market in the mid-19th century
- What was the rough number of individual editions of poetry, plays, and nonfiction prose on the London book market in the 19th century?
- How many of these were 19th century works, versus 18th-century works, 17th century, or 16th century works? Are there more or fewer per century than critics have thought?
- What authors besides the well-known ones were really prolific and able to publish a lot?
- How were these books organized? We have a set of codes that suggest an organization or classification for almost every one of Stainforth’s titles. It would simply take sorting them in alphabetical order to learn more about what these codes mean and how Stainforth grouped his books.
So with the goal in mind of producing data to answer these questions and more, I want to turn to our second challenge:
Challenge #2: You have your transcriptions, and you want to edit them for release in data files for computational analysis. How are you going to do this? Head back into our shared Google Doc with your group and brainstorm on this for the next few minutes. We’ll gather back together to discuss our questions and solutions. At 10am, I’m going to move on and show you how I’m approaching this.
Summary of Responses:
- Don’t do much! Let people’s use cases drive the direction of the markup.
- Do you want every stain inkblot and tear coded? Didn’t think so. That’s what the manuscript images are for.
- Do you need the transcription at all? What you really need is a database. Use the authorities database as the front end, and then point to the manuscript for location of the mention of the name on a certain page. [Note: this response, from someone who teaches TEI, made me second guess our entire approach to the project – maybe we have it backward?]
- Jay Satterfield and Peter Carini: the shelfmarks might not be shelfmarks. They could also be a classification system based on content. We have to wait and see!
Here’s how we are editing our transcription data for a data release sometime this summer.

I’ve dubbed this the “cookie dough” data release plan. It sounds non-academic, to be sure, and a bit cutesie, but I’m trying to illustrate widely to humanists who are just now learning how to evaluate digital projects that data alone is a worthwhile product — like cookie dough, which can be consumed and is delicious and desirable before it even makes it into the oven. To reiterate: edited and lightly tagged transcription data has value without deep encoding and without a fancy interface. It has value because there are a growing number of scholars within literary studies and bibliography, not to mention the social scientists, who know how to use computational analysis to craft an argument using data apart from an organizing interface. The cookie dough approach also includes the goal of eventually turning dough into actual cookies delivered on a plate, or delivering this data via an interface at a later time. That is, at a future date, the data will have nuanced and deep encoding, links where the data points to itself in a variety of ways, and it will be accessible in an interface that makes this digital resource user friendly for students, teachers, librarians, and researchers who want more structure than the code alone provides. Eating cookie dough does not preclude baking cookies.
The “cookie dough” data release plan helps digital humanists like myself use our data sooner for research we can publish and get traditional kinds of scholarly credit for in the form of peer-reviewed journal articles or book chapters. When you’re untenured and working your tail off, like me, that’s a huge draw. In contrast, getting credit for building a digital archive is certainly more and more possible, but risky, and may not result in any measurable credentials or gains for a scholar in the short term despite our [OUR as in all of us here in the library and our colleagues in neighboring fields] nuanced understanding of how much critical thought and editing it takes to produce one of these archives. It is absolutely a long act of scholarship, like a book project, to do so.
So: with data output as our near-term goal, I designed a multi-phase editorial plan that takes into account our transcriptions, that they need to be added to our database, but also lightly encoded and then transformed. And then they need to be prepared for the next stage of deeper encoding.
Here’s the overview of the plan:

Stepping away from the overview, I want to zoom in on what our editing looks like, sample resultant xml files, and the sample output from xslts.
Transcription editing: There are a few things to comment on here:
- What percentage of the files are we editing — 100%, every line. I received several suggestions to edit a smaller percentage of the files to make the editing process go faster. I couldn’t get comfortable with that, and some of my fellow editors felt the same way. We had multiple hands help with the transcription process, transcribers were all, including myself, sleep deprived and overworked while transcribing, so despite our diligence and care we were predisposed to human error. Therefore, I’m treating the data like sentences in a book project, and we’re reviewing every line.
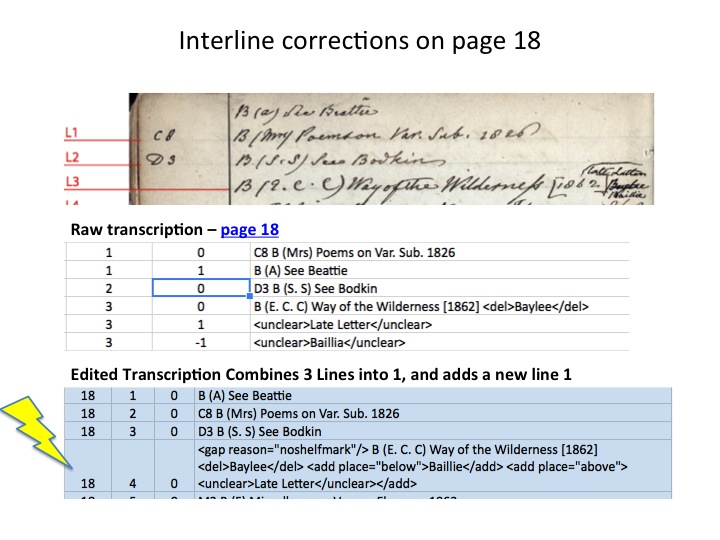 Interlines: We did away with interlines altogether and, in every instance included these in the parent-line entry using an set of tags. If the interline was a full entry of its own, we simply renumbered the lines on the ms pages and gave the entry its own line. The resultant page would have 25 lines instead of the usual 24. See the examples on the slide.
Interlines: We did away with interlines altogether and, in every instance included these in the parent-line entry using an set of tags. If the interline was a full entry of its own, we simply renumbered the lines on the ms pages and gave the entry its own line. The resultant page would have 25 lines instead of the usual 24. See the examples on the slide.- And surely on the “too crowded slide” above you noticed that line 4 of the edited transcription featured a tag that does not exist in the transcribed data. I’ll explain what we did there.

Remember those spaces in the manuscript that I mentioned earlier, the ones that stand in for the author’s repeated name in a list of works by the same author? The tag is our method of dealing with this and filling in the gap with the data it represents, but without hand-typing that data in on every line. This would muddy the line—remove it too far from a representation of the manuscript—and take far too much time. We’ll use an XSLTs to fill in these gaps with the names and titles they refer to. Here I want to acknowledge help from Laura Mandell and Matt Cristy, both at TAMU, in creating working XSLTs to do this.
We currently have 4 empty tags that we’re using to help us mark content where an absence on a line is actually content carried down from a line above.
- (rare – usually Stainforth marks this with a “Do.”)
The most important of these in terms of creating a data set is the first one, illustrated by the gentleman above who had a rough morning commute:
.
 What this tag does is it tells us that a part of the line has an empty space that stands in for a name — and more specifically, the name of the author last mentioned on the page when you read up the lines to — in this example — Mrs Cowley or Hannah Cowley.
What this tag does is it tells us that a part of the line has an empty space that stands in for a name — and more specifically, the name of the author last mentioned on the page when you read up the lines to — in this example — Mrs Cowley or Hannah Cowley.
The deep encoding solution for down the road is to have a personography for every author, and to link the gap to the parent person id on the line above as well as to the personography record in the database. Here’s an example of this from the Robert Bloomfield Letters project. You can see that in the letter, each person has his or her own person id, and this links to the corresponding entry in the personography. This slide shows an example for Capel Lloft.

Similarly, imagine “Cowley (Mrs)” and all of the blank spaces that should say “Cowley (Mrs)” linked to an authority personography record for her.
We are not doing this right now, but we’re saving it for a later stage, because:
- There are 500 pages of manuscript with up to 24 author entries per page — that is a lot of authors to encode identities for by hand. However, a related, bigger problem is that
- Early women authors can be very difficult to ascribe an identity to. One complicating factor is of course their birth name along with several possible married names, such as Anna Letitia Aikin who is known by both her family name, Aikin, and her married name, Barbauld.
- In addition to their family and several married names, a women authors published under pseudonyms – not just one per person, because that would be too easy, but multiple. For example, Lady Charlotte Bury is a late 18th-early 19th century poet and playwright. She has confusing married names and a number of additional pseudonyms based on the works she published. See the list in the slide.
 She was born Lady Charlotte Susan Maria Campbell, and her first married name was also Campbell because she married her cousin, Colonel Jack Campbell. For her second husband, she took the married name of Bury. She signed her work with the following additional names:
She was born Lady Charlotte Susan Maria Campbell, and her first married name was also Campbell because she married her cousin, Colonel Jack Campbell. For her second husband, she took the married name of Bury. She signed her work with the following additional names:
A Lady
A Lady of Rank
The Authoress of Flirtation
The Authoress of the Disinherited and Flirtation
The Author of The History of a Flirt
Author of Wilfulness of woman

Lady Emma Hamilton has more name-like pseudonyms, but perhaps they are better called variants, as the Library of Congress calls them. And they pose different problems because on their own, they simply look like the names for 5 different women.
Lady Hamilton
Emily Hart
Emma Hart
Amy Lyon
Emily Lyon
Emma Lyon
To complicate things, we discovered that in Stainforth she goes by Emma Lyon (page n275) — not mentioned by the LOC, as well as Hamilton, Mrs. E (page n193).

We must also consider the hundreds of women authors mentioned in Stainforth’s catalog who have abbreviated or incomplete identities not linked to a name and unidentifiable in an authority record like the LOC or Orlando, which makes assigning these authors IDs difficult. We can sometimes track identities down by Googling the titles and finding the author associated with it. However, it is often the case that when we track down the title, the author is specified as “A Lady” or another pseudonymous name.
Note: Stainforth tries to help his catalog user do exactly what we’re trying to do: match pseudonyms and initials to names. He does this with “See” references, and you can find examples of these on the “initials” slide in the B’s.
The upshot is that markup for person ids, catalog identities, and pen names is a monstrous research and encoding project in and of itself when dealing with a 600 page manuscript full of writers. These writers’ identities need to be properly cataloged – and really should be linked to one another – to afford them the recognition they deserve in a literary history that has repeatedly left most of them out.
For all of these reasons and more, I’ve decided that we’re going to produce curated data that meets some basic scholarly editorial standards and release that data for data mining before we deeply encode this data with person ids, titles ids, links to digital editions of the texts, and the like, and then build a GUI to access all of this.
Here’s what the text files will look like when we run them.

We now have cookie dough data, or data that can be analyzed using a computer program, and we’ve published it.
Challenge #3: For our third small group exercise I want you to imagine, with me, 2 scenarios of turning our data into a more traditional-functioning digital archive. We’ll meet again in our Google Doc for notes.
[Note – we did not get to challenge #3 due to the length of the conversation in challenges 1-2.]
The first scenario is grounded in the constraints of untenured faculty who are digital humanists with limited time, labor, and with some technology skills. For the first scenario, I would like you to gather together links of digital archives that you know — either you’ve helped build them or you know of them — that you think would serve as a great model for what the Stainforth digital archive will look like and work like in the future. Bear in mind that there will be approximately 2 full time people doing this, most likely me and one other person.
For the second scenario, go big and dreamy – no constraints. I want you to think about what digital archives cannot do that you want the Stainforth library or any archive to be able to do. What functionality would be the most useful or cool — nevermind that it might take an astronaut or an squad of programmers to generate that functionality.
For both scenarios, assume that we have finished collecting authorities data for all of the authors and titles in the library. Every title is linked to a digital edition, and every author has an authority record where there is one. Those authors that are unknown are tagged as such. Sketch or brainstorm as a group and then we’ll discuss it together.
Challenge 4: Preservation

For the 4th and last working group discussion, I want to lob the question of sustainability and maintenance. How do we keep the Stainforth digital library and digital archive relevant, in use, and updated for a period of time. How long should we expect to need to do this for?
[Note: we didn’t get to challenge 4. There was too much good conversation around challenges 1-2, which occasionally touched on the topic of sustainability.]
Conclusion: Data Curation for Computational Analysis (aka the “cookie dough” method) as Pragmatic Response
Producing and releasing the data first, and the more marked-up data set in a linked digital archive second, is a model that responds to the constrained institutional ecosystem in which untenured digital humanist faculty are working. It also helps us make more useful digital objects with the same amount of data. As far as I know, no other projects are approaching data curation this way, and perhaps that is because other large textual digitization projects are managed by tenured faculty with job security and who have already produced enough traditional scholarship to spend time on a riskier longterm project.
First, we will release our data for computational analysis, and then after more tagging and linking, we will release it again with the addition of a GUI. The “cookie dough” method is a solution to the problem that junior faculty digital humanists must wrestle with: we’re untenured and, in general, expected to publish on traditional literary topics in addition to producing digital objects. We need to produce digital scholarship that can be evaluated to help us advance our careers. With the status of digital archives so iffy in terms of what counts for hiring and tenure, and with no guidelines at all, yet, for the evaluation of data sets we produce, it makes sense to use what we’re already building to support traditional publications in peer-reviewed journal articles—scholarship with clear currency–driven by the data we’re working so hard to curate. Additionally, I’m encouraged that the findings from analyzing and writing about my data, as well as seeing what others scholars do with it, will yield insights that will help the process of completing the digital archive. I have found it to be true that the better you know your data and what others want to do with it, too, the better you can design its delivery mechanism or interface.
Thank you.

[…] instance in which I got to know the writers in our data better occurred in response to a talk I gave to librarians at Dartmouth last Spring. After my talk, a colleague in the libraries emailed […]
[…] Read the blog version of this talk: here. […]